















你有没有想过,在浩瀚的网络世界里,有一种工具能帮你轻松抓取视频,让你随时随地享受精彩内容?没错,今天就要来聊聊这个神奇的宝贝——Scrapy,还有它如何帮你轻松搞定视频下载。
Scrapy:视频抓取的得力助手
Scrapy,这个名字听起来是不是有点高大上?别看它名字听起来复杂,其实它是一款非常实用的Python爬虫框架。它可以帮助我们轻松地从网站中抓取数据,包括图片、文本、甚至是视频。那么,Scrapy是如何做到的呢?
首先,Scrapy会发送一个HTTP请求到目标网站,获取网页内容。它会解析这些内容,提取出我们感兴趣的数据。这个过程就像是一个勤劳的小蜜蜂,在互联网上飞来飞去,收集着各种信息。
而说到视频,Scrapy同样可以大显身手。它可以通过分析网页的HTML结构,找到视频的URL,然后将其下载到本地。是不是听起来很神奇?其实,只要你掌握了Scrapy的用法,这一切都可以轻松实现。
Scrapy视频抓取的步骤解析
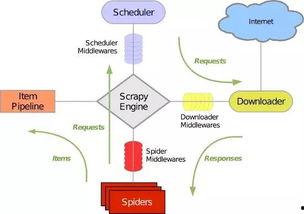
那么,具体来说,如何使用Scrapy来抓取视频呢?下面,就让我带你一步步走进Scrapy的世界。
1. 安装Scrapy

首先,你需要安装Scrapy。打开命令行,输入以下命令:
pip install scrapy
安装完成后,你就可以开始使用Scrapy了。
2. 创建Scrapy项目
创建一个Scrapy项目,可以让你更好地组织你的爬虫代码。在命令行中,输入以下命令:
scrapy startproject myproject
这里,`myproject` 是你的项目名称,你可以根据自己的喜好来命名。
3. 编写爬虫
进入项目目录,创建一个爬虫文件。在文件中,你需要定义爬虫类,并编写爬取逻辑。以下是一个简单的爬虫示例:
```python
import scrapy
class VideoSpider(scrapy.Spider):
name = 'video_spider'
start_urls = ['http://example.com/videos']
def parse(self, response):
for video_url in response.css('video::attr(src)').getall():
yield scrapy.Request(video_url, callback=self.save_video)
def save_video(self, response):
video_path = 'videos/' response.url.split('/')[-1]
with open(video_path, 'wb') as f:
f.write(response.body)
在这个例子中,我们定义了一个名为`VideoSpider`的爬虫类,它从`http://example.com/videos`这个页面开始抓取视频。我们通过解析HTML结构,找到视频的URL,并将其保存到本地。
4. 运行爬虫
在命令行中,输入以下命令来运行爬虫:
scrapy crawl video_spider
运行完成后,你就可以在项目目录下的`videos`文件夹中找到下载的视频了。
Scrapy视频抓取的注意事项
在使用Scrapy抓取视频时,需要注意以下几点:
1. 遵守网站robots.txt规则:在抓取数据之前,请确保你遵守目标网站的robots.txt规则,以免侵犯网站权益。
2. 合理设置请求频率:为了避免给目标网站带来过大压力,请合理设置请求频率。
3. 处理异常情况:在实际抓取过程中,可能会遇到各种异常情况,如网络错误、数据解析错误等。请确保你的爬虫能够妥善处理这些异常情况。
4. 尊重版权:在抓取视频时,请确保你有权使用这些视频,避免侵犯版权。
Scrapy是一款非常强大的爬虫工具,可以帮助你轻松抓取视频。只要掌握了Scrapy的用法,你就可以在互联网上尽情畅游,享受各种精彩内容。快来试试吧!
转载请注明来自精品女性网,本文标题:《scrapy 视频,轻松实现视频内容抓取与概述生成》








 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号